Table of Contents
Introduction
Purpose of Software Quality Plan
The purpose of a Data Warehouse Development Quality Plan is to ensure that the development, deployment, and maintenance of the data warehouse, along with its associated components such as third-party data sources, Azure Data Factory (ADF) pipelines, and Data Marts, meet established quality standards. This plan serves as a comprehensive guide outlining the processes, methodologies, and quality assurance measures to be implemented throughout the data warehouse lifecycle.
Terms of Reference
Purpose of system, users of system, overview of technical approach
Data Governance Organisation (sharepoint.com)
Data Governance Procedure
Data Exploitation Procedure
Quality Assurance of Data & Analytic Products
Data Quality Procedure
Data Relevance Procedure
Data Integrity Procedure
Data Strategy
QA Requirements
Quality standards that apply to the development. Software Lifecycle used Software Quality tool(s) and methods used.
The overarching goal of Data Warehouse Development Quality Plan is proactive problem-solving, where any anomalies or discrepancies are swiftly identified and rectified before they escalate into issues. Through continuous monitoring, analysis, and data observability, the reliability, accuracy, and accessibility of the data assets are maintained, thereby fostering trust and confidence in data-driven decision-making.
- Principles of Data Observability
| Principle | Activity | So that … |
| Freshness | Ensure that data is up-to-date and reflects the most recent state of the source systems | users can make decisions based on timely and accurate information, leading to more informed and effective actions. |
| Distribution | Monitor how data is spread across systems and locations to ensure that it falls within acceptable ranges and thresholds | potential issues such as data skew or imbalance can be identified and addressed promptly, maintaining data quality and integrity across the distributed environment. |
| Volume | Track the volume of data being ingested, processed, and stored | capacity planning and resource allocation can be optimised, preventing infrastructure overload or resource contention and maintaining efficient data processing. |
| Schema | Validate data schema consistency and evolution over time | data compatibility and interoperability are maintained, preventing errors and inconsistencies that could disrupt downstream processes or analyses. |
| Lineage | Capture and visualise the lineage of data, including its origins, transformations, and destinations | data provenance and impact analysis can be performed, enabling users to trace data back to its source and understand its journey through the data pipeline. |
Security Requirements
Security specific requirements for the project. Assessment of changes on existing system security.
The confidentiality, integrity, and availability (CIA) model is widely used by organisations to implement appropriate security controls and policies, which helps identify key problem areas and the necessary solutions to resolve these issues.
- the data can be accessed, altered, disclosed or deleted only by those you have authorised to do so (and that those people only act within the scope of the authority you give them);
- the data held is accurate and complete in relation to why we are processing it; and
- the data remains accessible and usable.
Access Control and Authorisation:
Role-based access mechanisms and strict authentication measures SHALL be enforced by IT Security and Data Engineering to mitigate unauthorised access risks.
Data Accuracy and Completeness:
Data Specialists SHALL conduct regular audits and validations to ensure that the data aligns with the intended purpose of processing, thereby upholding data integrity.
Data Recovery and Resilience:
Data Engineering SHALL facilitate the timely restoration of data in the event of accidental loss, alteration, or destruction.
Encryption and Data Protection:
Data encryption techniques SHALL be used to safeguard data both at rest and in transit, thereby maintaining data confidentiality.
Monitoring and Incident Response:
Data Engineering and IT Security SHALL develop incident response procedures to swiftly address any security incidents and mitigate their impact on data confidentiality, integrity, and availability.
Compliance and Governance:
Data Engineering SHALL implement governance frameworks to enforce data protection policies and procedures, thereby fostering accountability and transparency in data handling practices.
Scope of Task
Scope covered by the project and any documents received.
Technical Perspective
The Data Warehouse Development Quality Plan describes the creation, organisation, movement, change and storage of data from the perspective of the technical and physical implementation.
The scope of the Data Warehouse Development Quality Plan encompasses the following key areas:
- Data Planning
- Data Acquisition
- Data Processing & Maintenance
- Data Publishing & Sharing
- Snapshot & Archive
Business Perspective
The business perspective is defined by the data specialist and stewards defining business requirements for data, only then can data engineering be able interpret these to execute the requirements to provide the data. Quality issue occur when the business requirements are not clear or if a business term is bound to multiple data elements.
For example…
If we were to imagine asking for the organisation’s definition of a ‘customer’. It could be an IFS Account ID, it could be a payor in Sage, it could be a customer number in HubSpot.
The point is that the business term may have different (or encompass multiple) data elements depending on the context and the only reasonable way for a technical oriented stakeholder to execute the business requirements is to have the capability to look it up in a catalogue, trace its lineage, extract/process the data, and ultimately provision it back to the ‘Business View’.
Source and Third-Party Perspective
The most common cause of production-specific data quality issues is the ingestion of third-party data sources. This is because there is no control over the underlying data; it can be reliable at one moment but suddenly change without notice. These issues may also be difficult to fix immediately, thereby persisting for some time without resolution.
Project Organisation
People involved and their roles, chains of command and reporting methods, distribution list of SQP.
Data Steering Committee
- Business led, IT assisted.
- Holders of the decision rights for the governance policies enacted.
- Define goals, rules, and policies for the program.
- Approve, fund, and prioritise projects to address data and analytics needs.
Data Stewards
- Act as liaisons between the business and the D&A and IT teams.
- Enforce data and analytics governance policies and standards created by the steering committee.
- Manage and resolve deviations and exceptions to policies
Data Specialists
- Act as custodians and help with maintenance for specific data.
- Partner with data stewards to implement data transformations, resolve data issues and collaborate on system changes.
Quality Behaviours of Data Specialists
- Leading and promoting a culture that values and protects data.
- Knowing what data you manage and why.
- Knowing who has access to the data whilst you are responsible for it and why.
- Understanding and addressing risks to the data whilst you are responsible for it.
- Ensuring the data is used efficiently and effectively to achieve your department’s and the BMT’s vision.
- Acting as the nominated “owner” of an assigned data asset(s) on behalf of your department and the BMT.
- Ensuring that the data is processed for purposes consistent with the strategic objectives of your department.
- Determining how the data is collected, processed, retained and disposed of within your department in line with the overarching BMT framework; and
- Working with other Data Specialists to collaborate on internal data sharing arrangements.
Data Engineering
- Develops and constructs data products and services (Data Marts),and integrates them into systems and business processes.
- Provides support for the development and maintenance of data analysis/analytics systems though Data Mesh Principles.
Data Mesh Principle
The Data Mesh decentralises data ownership by transferring the responsibility from the central data team to the business units that create and consume data.
By decentralising data ownership to domain teams, Data Mesh promotes agility, innovation, and accountability within BMT. It enables faster decision-making, facilitates collaboration across business units, and empowers domain experts to derive actionable insights from data more effectively.
Data Engineering operates on the principles of domain-driven design, product thinking, and federated governance.
| Principle | Activity | So that… |
| Domain-oriented Decentralised Data Ownership and Architecture: | Implement data flows to seamlessly connect operational systems with analytics and business intelligence (BI) systems | domain teams can own and manage their data independently, fostering agility and innovation within their domains. |
| Data as Product: | Document clear source-to-target mappings for transparency and traceability | data is treated as a valuable product, ensuring that it is well-understood, curated, and accessible for consumption by domain teams. |
| Self-service Infrastructure as a Platform: | Provide a data developer portal (myBMT & Knowhow) Direct data access with Command GET and API services | domain teams can autonomously access and utilise data infrastructure and tools, enabling them to build, deploy, and manage data pipelines and applications without the need for extensive support from centralised teams. |
| Federated Computational Governance: | Provide support for the development and maintenance of data analysis/analytics systems (myBMT & Knowhow) | Best practice and computational learning can be distributed, allowing domain teams to govern their data processing and analytics workflows according to their specific needs and requirements. |
Review Meetings
Frequency, location and style of meetings, who should attend. To include standups/sprint meetings, code review methods and end of project review.
Incorporating an Agile approach forms an integral aspect of the Data Engineering development process. By dividing the development cycle into smaller segments, iterations, and sprints, Agile methodologies enable engineers and data specialists to collaborate seamlessly with the wider team. This facilitates prompt identification and rectification of features and errors as they arise. The primary objective of this approach is to swiftly deliver new DataMart features while maintaining quality standards.
Consequently, this method proves to be less time-intensive, as it addresses errors early in the development phase, thereby mitigating the risk of compounding issues. Furthermore, it requires less managerial oversight. Effective team communication and proactive stakeholder involvement accelerate the process and cultivate informed decision-making.
Data Engineering operates within a weekly sprint framework, with an integrated review period extending the effectiveness of the sprint delivery to a bi-weekly cycle. This incorporation allows for a more comprehensive assessment of progress and ensures a refined output within the two-week sprint timeline.
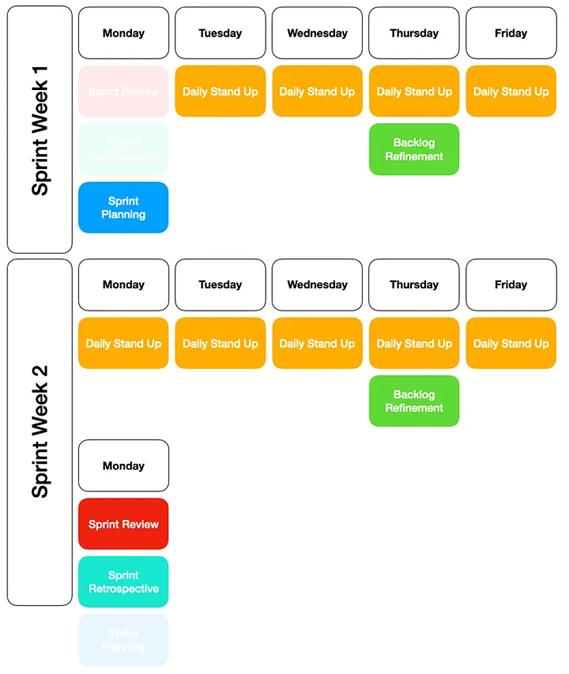
The Data Engineering and Analysis Working Group currently reviews the Sprint Plan on Tuesday morning, with Backlog Refinement on Thursday.
Deliverables
SQP, requirements catalogue, package details, method of rolling out.
DataMart Lifecycle (Development Plan)
| Output | Purpose | Owner | Location |
| Data Source Inventory | Identify relevant data sources within the organisation, including databases, applications, and external sources. | Data Architect/Engineer (with Data Specialist) | myBMT(Data Objects) |
| Data profiling reports | Profile data sources to understand data quality, structure, and relationships. | Data Architect/Engineer (with Data Specialist) | myBMT(Data Fields) |
| Business requirements document | Gather business requirements and user needs for the DataMart. | Data Specialist (with Data Architect/Engineer) | DataMart Design Specification (Functional Spec) |
| Stakeholder alignment summary[SW1] | Align with stakeholders to ensure project objectives and expectations are clear. | Data Specialist (with Data Architect/Engineer) | DataMart Design Specification (User Stories) |
| Output | Purpose | Owner | Location |
| Data models (conceptual, logical, physical) | Design conceptual, logical, and physical data models for the DataMart. | Data Architect/Engineer (with Data Specialist) | DataMart Design Specification (DrawIO) |
| Schema diagrams | Define the schema for tables and relationships within the DataMart. | Data Architect/Engineer | SnapShot Design |
| Architecture design document | Determine the technology stack, infrastructure requirements, and integration points for the DataMart. | Data Architect/Engineer | Medalion Pipeline Design |
| Security and access control specifications | Design security measures and access controls to protect data within the DataMart. | Data Specialist (with Data Architect/Engineer) | DataMart Design Specification (Method of Deployment) |
| Output | Purpose | Owner | Location |
| Minimum viable version of the DataMart with essential features implemented | Identify and prioritise essential features and functionalities based on user needs and business requirements. | Data Architect/Engineer (with Data Specialist) | Power BI Wireframe/PoC (DE&A Workspace) myView Design (DEV) |
| Prototypes or Report mock-ups demonstrating key features and workflows | Develop prototypes or report mock-ups to visualise and validate the MVP’s key features and user workflows. | Data Architect/Engineer (with Data Specialist) | Power BI Wireframe/PoC (DE&A Workspace) |
| Test reports and validation results | Conduct testing to ensure that the MVP meets user expectations and quality standards. | Data Specialist (with Data Architect/Engineer) | myBMT (Tickets) Bug & Change Request |
| Stakeholder feedback and iteration log | Gather feedback from stakeholders and users to iterate on the MVP and refine its features and functionality. | Data Specialist | myBMT (Tickets) Bug & Change Request |
| Output | Purpose | Owner | Location |
| Deployed DataMart system | Deploy the DataMart into production, ensuring it is accessible, reliable, and secure. | Data Architect/Engineer (with Data Specialist) | System Test DataMart (beta) PowerBI Wireframe/PoC (DE&A Workspace) |
| Test reports and validation results. | Conduct testing to ensure data accuracy, system performance, and user acceptance. | Data Specialist (with Data Architect/Engineer) | Acceptance Test DataMart (beta) PowerBI (UAT Workspace) |
| User training materials and documentation | Provide training for users and administrators and create documentation for system usage and maintenance. | Data Architect/Engineer | KnowHow |
| Deployment and go-live checklist | Deploy the DataMart into production environment, monitor performance, and address any issues during go-live. | Data Architect/Engineer (with Data Specialist) | Up-Rev DataMart PowerBI (PRD/Live Workspace) |
Exit Criteria
As there is no perfect data product, the testing is never 100 percent complete. It is an ongoing process. However, there exists the so-called “exit criteria”, which defines whether there was “sufficient testing” conducted, based on the risk assessment of the project.
There are common points that are present mostly in exit criteria:
- Test case execution has been executed by Data Engineering.
- A system has no high priority defects.
- Performance of the system is stable regardless of the introduction of new features.
- The DataMart Product supports all necessary platforms
- User Acceptance Testing is completed
- Changes have been documented
[SW1]Do we have templates for these?
Testing and Quality
Assurance System Test, Regression Test, Unit Test activities, UA Tests, Peer Reviews (with estimated dates), code review methodology (Pull Requests/Pair Programming/other)
A new DataMart feature is more than several lines of code. It is usually a multilayer, complex pipeline system, incorporating separate functional components and third-party data integrations. Therefore, efficient development testing should go far beyond just finding errors in the source code. Typically, the testing covers the following levels of data engineering.
- Component/Unit testing
- Integration testing
- System testing
- Acceptance testing
Each level ensures thorough validation of the feature’s functionality, interoperability, and alignment with user requirements.
Component/Unit testing
The smallest testable part of the Data Warehousing system is often referred to as a unit. Therefore, this testing level is aimed at examining every single unit of a system in order to make sure that it meets the original requirements and functions as expected. Unit testing is commonly performed early in the development process by the engineers themselves.
Integration testing
The objective of the next testing level is to verify whether the combined units work well together as a group. Integration testing is aimed at detecting the flaws in the interactions between the units within a pipeline module.
System testing
At this level, a complete DataMart system is tested as a whole. This stage serves to verify the product’s compliance with the functional and technical requirements and overall quality standards. System testing should be performed in a development context using an environment as close to the real business use scenario as possible.
DataMart regression testing in the last stable version ensures that the system’s data retrieval processes remain consistent and accurate across the feature updates or modifications. This testing phase involves executing a series of predefined queries against the DataMarts to validate that the expected data is returned as per the defined criteria.
Acceptance testing
This is the last stage of the testing process, where the product is validated against the end user requirements and for accuracy. This final step helps the team decide if the data product is ready to be made available or not. While small issues should be detected and resolved earlier in the process, this testing level focuses on overall system quality, from content and UI to performance issues. The acceptance stage might be followed by an alpha and beta testing, allowing a small number of actual users to try out the software before it is officially released[SW1] [JK2] .
- Levels of Testing
| Unit Testing | Integration | System | Acceptance | |
| Why | To ensure features and code is developed correctly | To make sure the ties between the system components function as required | To ensure the whole system works well when integrated | To ensure customer’s and end user expectations are met |
| Who | Data Architect & Developer | Module/Pipeline Technical Architect | Data Engineer & Data Specialist | Data Specialist & Product Owner |
| What | All new code + refactoring of legacy code as well as SQL/JavaScript/Python unit Testing | Azure web services, synapse pipeline modules | User flows and typical User Journeys, Performance and security testing | Verifying acceptance tests on the stories, verification of features |
| When | As soon as new code is written | As soon as new components are added | When the data product is complete | When the data product is ready to be shipped |
| Where | Staging, Local & SQL DEV – Continuous Integration (CI) (Bronze & Silver) | Azure DEV environment | Azure DEV Continuous Deployment (CD) (Gold) | PRD beta version |
| How (tools and methods) | Visual Studio, Azure Data Studio, SSMS, GIT/DevOps | Synapse, ADF, Python Notebook | SQL DEV | SQL PRD, myBMT, KnowHow |
| Actions | Check Bronze Processed file is available and Create Snapshot SQL | Check SQL for Spark and Python integration | Create MyView (mvw) in DEV | Create MVW in PRD (beta), update Knowhow |
In agile Data Engineering and feature development, the testing typically represents an iterative process. While the levels generally refer to the complete product, they can also be applied to every added feature. In this case, every small unit of the new functionality is being verified. Then the Technical Architect checks the interconnections between these units, the way the feature integrates with the rest of the system and if the new update is ready to be shipped.
[SW1]What about regression testing to test the integrity of changes on the existing data pipelines when another change is made?
[JK2]Yes I am suffering as a result here
Reporting
Reporting of progress to customer/project manager[SW1] [JK2] .
Data Engineering SHALL use a Jira(R) style ticket management tool to plan, track and release tickets and tasks for the purpose demonstrating the entire development lifecycle. Allowing the wider team to move work forward, stay aligned and communicate in context.
Data Engineering has chosen to use an Open Source (PHP based) software tool with login access, branded as myBMT
https://bmt-dwh-uks-app-my.azurewebsites.net/index.php
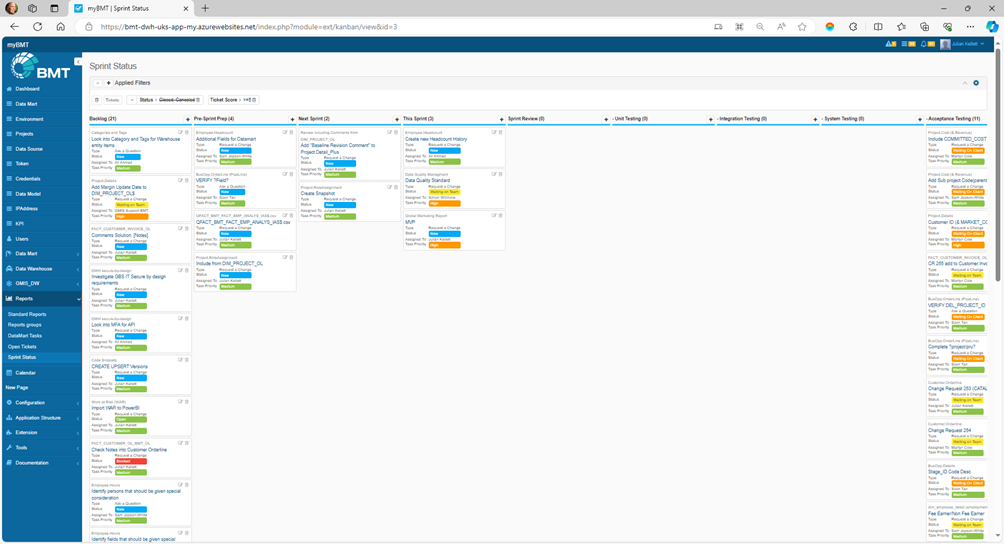
myBMT for agile teams
For teams who practice agile methodologies, myBMT provides scrum and kanban boards out-of-the-box. Boards are task management hubs, where tasks are mapped to customisable workflows. Boards provide transparency across teamwork and visibility into the status of every work item.
myBMT supports any agile methodology for software development.
myBMT for project management teams
myBMT issues, also known as tasks, track each piece of work that needs to pass through the workflow steps to completion. Customisable permissions enable admins to determine who can see and perform which actions. With all project information in place, reports can be generated to track progress, productivity, and ensure nothing slips.
myBMT for development teams
myBMT provides planning and tracking tools so teams can manage dependencies, feature requirements, and stakeholders. CI/CD integrations facilitate transparency throughout the software development life cycle.
myBMT for task management
Create tasks for yourself and members of your team to work on, complete with its details, due dates, and reminders. Utilise subtasks to breakdown larger items of work. Allow others to watch the task to track its progress and stay up to date with email notifications.
myBMT for bug tracking
Bugs are just a name for to-do’s stemming from problems within the software a team is building. It is important for teams to view all the tasks and bugs in the backlog so they can prioritise big picture goals.
[SW1]I think we should make reporting here align to the meetings structure to help us regularly review that planned changes are being QA and progressed. Issues can be escalated to the Data Steering Committee as required.
[JK2]Can talk about tickets and KanBan
Design Methodologies and Environment
Design methodology, development platform, hardware requirements, database. All Software Quality Procedures
Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration and Continuous Deployment (CI/CD) ensures that changes and updates to data pipelines are tested, integrated, and deployed to production, facilitating consistent and reliable data processing and delivery. In dynamic data environments where sources, formats, and requirements evolve rapidly, CI/CD provides a robust framework for handling these changes.
Continuous Integration (CI)
Continuous Integration is an agile practice where developers frequently integrate their code changes into a shared repository, ideally several times a day. Each integration is verified by building the application in the development environment and running tests against it. The main goals of CI are to detect errors quickly, reduce integration problems, and ensure that the software is always in a potentially releasable state.
Continuous Deployment (CD)
Continuous Deployment is an extension of Continuous Integration that focuses on deploying every change that passes the quality tests into production. The goal is to deliver new features, improvements, and bug fixes to users as quickly and safely as possible without manual intervention.
CI/CD in Data Engineering
Specifically, in Data Engineering, CI/CD facilitates the testing of new ETL code, validates data schemas, monitors data quality, detects anomalies, deploys updated data models to production, and ensures proper configuration of databases and data warehouses. This rigorous process guarantees that changes are thoroughly tested and seamlessly integrated into production environments.
By implementing CI/CD in Data Engineering, the team can handle rapid changes in data environments, maintain high-quality data processing, and ensure reliable delivery of data to stakeholders.
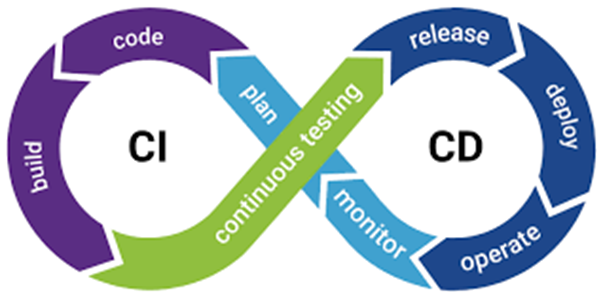
- CI/CD Development Lifecycle
Common Data Model
At the core of BMT’s data warehouse architecture is the Common Data Model (CDM), which serves as the foundation for representing the organisation’s core business processes and common form designs. The CDM supports dimensional modelling, where data is structured into measurement facts and descriptive dimensions, enabling efficient querying and analysis. Dimensional models, instantiated as star schemas or cubes in relational databases, provide a structured framework for organising and accessing data, facilitating reporting and analytics processes.
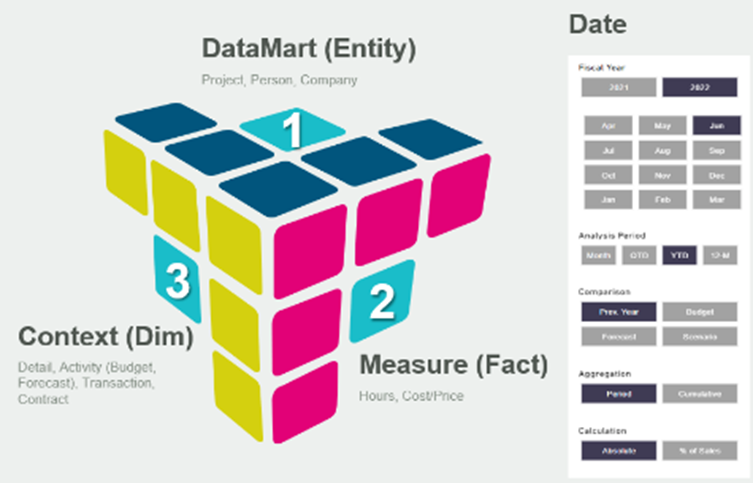
Common Data Model (Cube)
Medallion Lakehouse architecture
The Medallion Lakehouse represents successive levels of data refinement, with each stage adding value and sophistication to the data as it progresses towards its ultimate purpose of enabling informed decision-making and driving business success.
Bronze Data Layer:
The bronze stage focuses on ingesting raw data from multiple sources without much transformation. The emphasis is on capturing all available data in its original form, ensuring completeness and preserving the integrity of the source data. Quality checks are applied to identify and address any issues with data integrity or consistency. The goal of the bronze stage is to create a foundational dataset that serves as the basis for further processing and refinement.
- Maintains the raw state of the data source.
- Is appended incrementally and grows over time.
- Can be any combination of streaming and batch transactions.
Silver Data Layer:
In the silver stage, the raw data from the bronze pipeline undergoes additional processing and transformation to make it more structured and usable for analysis. This involves cleaning the data, standardising formats, resolving inconsistencies, and enriching it with additional context or metadata. Data quality checks are intensified to ensure accuracy and reliability. The silver stage produces a refined dataset that is well-prepared for analytical purposes and serves as a reliable source for business insights.
- Silver Layer represents a validated, enriched version of our data that can be trusted for downstream analytics.
Gold Data Layer:
The gold stage represents the highest level of refinement in the data pipeline. Here, the data is further enhanced and optimised for specific analytical or operational needs. Advanced transformations, aggregations, and calculations are applied to derive valuable insights and support decision-making processes. Data governance measures are rigorously enforced to maintain data integrity, security, and compliance. The gold stage delivers curated datasets of the highest quality, providing actionable insights that drive business outcomes and strategic initiatives.
- Gold tables represent data that has been transformed into knowledge, rather than just information.
- Analysts largely rely on gold tables for their core responsibilities, and data shared with a DataMart would rarely be stored outside this level.
Development Programme
Project Plan or other project management document.
Data Discovery Stage:
Objective:
Identify data sources, understand data requirements, and define the scope of the DataMart project.
Key Activities:
- Data Source Identification: Identify relevant data sources within the organisation, including databases, applications, and external sources.
- Data Profiling: Profile data sources to understand data quality, structure, and relationships.
- Requirements Gathering: Gather business requirements and user needs for the DataMart.
- Stakeholder Alignment: Align with stakeholders to ensure project objectives and expectations are clear.
Deliverables:
- Data source inventory
- Data profiling reports
- Business requirements document
- Stakeholder alignment summary[SW1]
Design Stage:
Objective:
Design the architecture, schema, and data models for the DataMart.
Key Activities:
- Data Modelling: Design conceptual, logical, and physical data models for the DataMart.
- Schema Design: Define the schema for tables and relationships within the DataMart.
- Architecture Design: Determine the technology stack, infrastructure requirements, and integration points for the DataMart.
- Security and Access Control: Design security measures and access controls to protect data within the DataMart.
Deliverables:
- Data models (conceptual, logical, physical)
- Schema diagrams
- Architecture design document
- Security and access control specifications
MVP (Minimum Viable Product) Stage:
Objective:
Develop and deploy a minimum viable version of the DataMart with essential features and functionality.
Key Activities:
- Feature Prioritisation: Identify and prioritise essential features and functionalities based on user needs and business requirements.
- Prototype Development: Develop prototypes or report mock-ups to visualise and validate the MVP’s key features and user workflows.
- Development Iteration: Implement the prioritised features and functionalities in an iterative and incremental manner.
- Testing and Validation: Conduct testing to ensure that the MVP meets user expectations and quality standards.
- Feedback Collection: Gather feedback from stakeholders and users to iterate on the MVP and refine its features and functionality.
- Refinement and Optimisation: Iterate on the MVP based on feedback, refining features, improving usability, and optimising performance.
Deliverables:
- Minimum viable version of the DataMart with essential features implemented
- Prototypes or Report mock-ups demonstrating key features and workflows
- Test reports and validation results
- Stakeholder feedback and iteration log
Deployment Stage:
Objective:
Deploy the DataMart into production, ensuring it is accessible, reliable, and secure.
Key Activities:
- Environment Setup: Provision infrastructure and environments for development, testing, and production.
- Data Integration: Extract, transform, and load (ETL) data from source systems into the DataMart.
- System Configuration: Configure software, databases, and tools required for the DataMart.
- Testing and Validation: Conduct testing to ensure data accuracy, system performance, and user acceptance.
- Training and Documentation: Provide training for users and administrators and create documentation for system usage and maintenance.
- Deployment and Go-Live: Deploy the DataMart into production environment, monitor performance, and address any issues during go-live.
Deliverables:
- Deployed DataMart system
- Test reports and validation results.
- User training materials and documentation
- Deployment and go-live checklist.
[SW1]Do we have templates for these?
Control of Data
Identification of controlled data, its classification, and associated processes.
Data Identification
Inventory of Data Assets
Data Cataloguing: Create a comprehensive inventory of all data assets across your organisation, including databases, data warehouses, data marts, and data lakes.
Data Source Mapping: Identify and map all data sources, including internal systems and third-party sources.
All Data Sources SHALL be described in myBMT
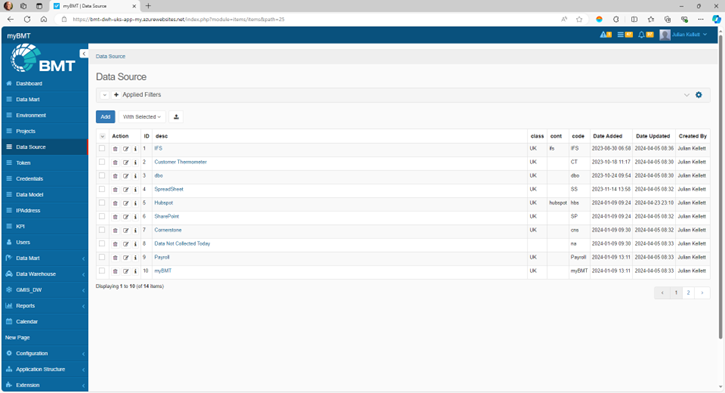
The EA solution SHALL map the Enterprise solutions and interactions
Data Discovery Tools
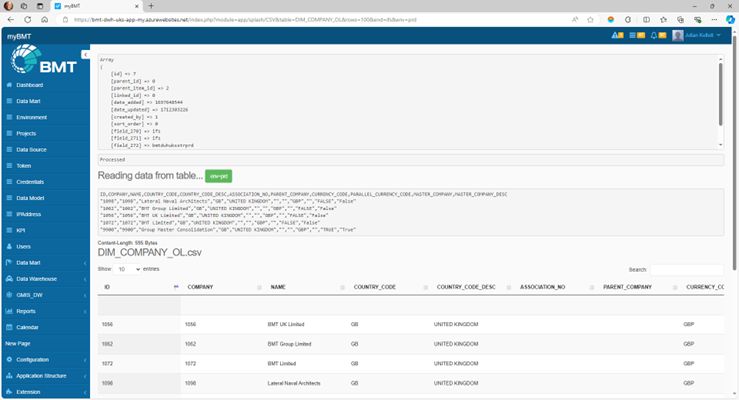
User Discovery: All data sources that are in-scope are discoverable to authorised users including exploration of data within the export.
myBMT SHALL support data discovery by showing splash views of data container objects
Data Classification
Define Classification Levels
Sensitivity Levels: Establish clear classification levels (e.g., Public, Internal, Confidential, Restricted) based on data sensitivity and regulatory requirements.
Classification Criteria: Define criteria for each classification level, considering factors such as data type, usage, impact of disclosure, and regulatory implications.
Sensitivity Levels SHALL be defined by the DataMart Owner in the DPIA
The schema mvw and dvw SHALL be the public view
Confidential data SHALL be in alternative schema (e.g. fa for financial)
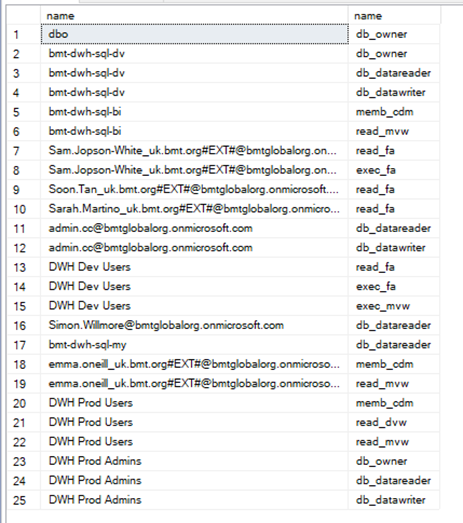
Alternative Schemas SHALL have Restricted access policy applied
Tagging and Labelling
Data Tagging: Implement data tagging mechanisms to label data according to its classification level.
Metadata Management: Use metadata management tools to store and manage classification tags and labels.
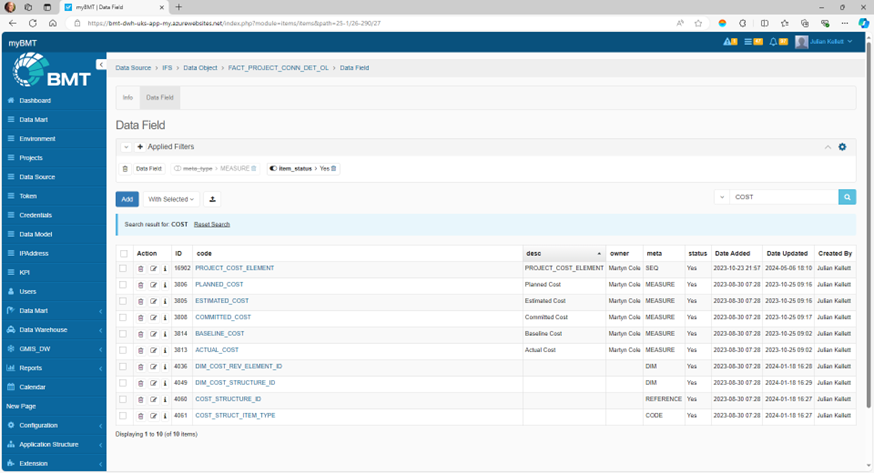
Data SHALL be tagged for metadata classification (e.g. Date, Measure, Code/Dim, Sequence)
Data SHOULD be tagged for owner
Data Fields SHOULD be described in myBMT
Associated Processes
Access Control
Role-Based Access Control (RBAC): Implement RBAC to ensure that users have access only to the data necessary for their roles.
Least Privilege Principle: Apply the least privilege principle to minimise access to sensitive data.
There SHALL be two Database access groups Data Admin and Data User
Data Admin SHALL be the System Administrator and DB Owner
Data User SHALL be the public access group
Data User SHALL be member of the Common Data Model and read access to mvw and dvw
Other Read access SHALL be explicitly applied
All users SHALL access via Microsoft Entra/MFA
Azure applications SHALL access via SQL User ([dv] (read/write all), [my] (read all))
The user [bi] SHALL be used to validate user access for Data User
Data Handling Procedures
Data Handling Policies: Develop and enforce data handling policies for each classification level, detailing how data should be accessed, stored, transmitted, and disposed of.
Data Encryption: Use encryption for sensitive data both at rest and in transit.
Data Handling Policy SHALL be described by the Data Owner in the DPIA
Monitoring and Auditing
Activity Monitoring: Implement continuous monitoring of data access and usage to detect unauthorised access and potential breaches.
Audit Trails: Maintain detailed audit trails of data access and modifications for accountability and compliance.
All source data SHALL be archived before processing
Transfer Logs SHALL be applied to each stage of the Pipeline
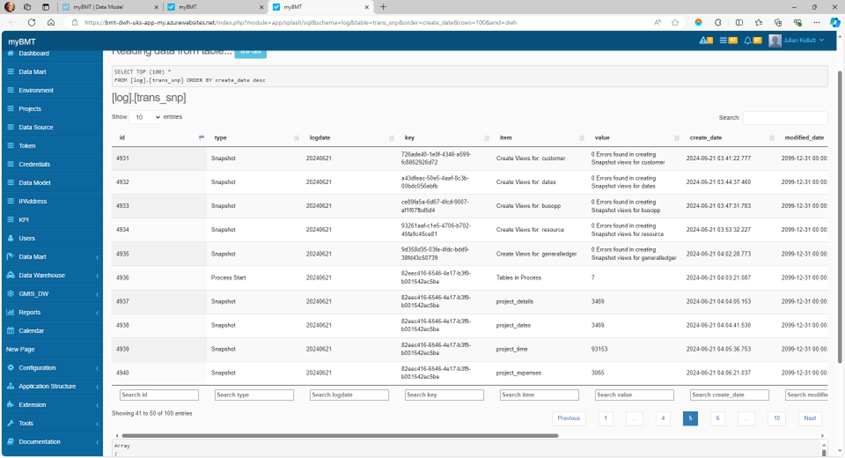
Execution by external Agent SHALL be recorded to identify the Agent (ReportID) and Calling User
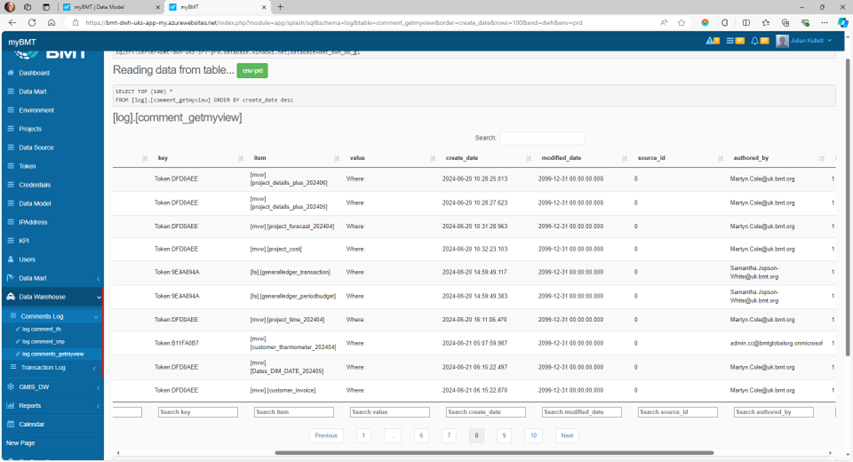
All Data Views (DataMarts) SHALL be checked that
- They open without error
- They contain row data
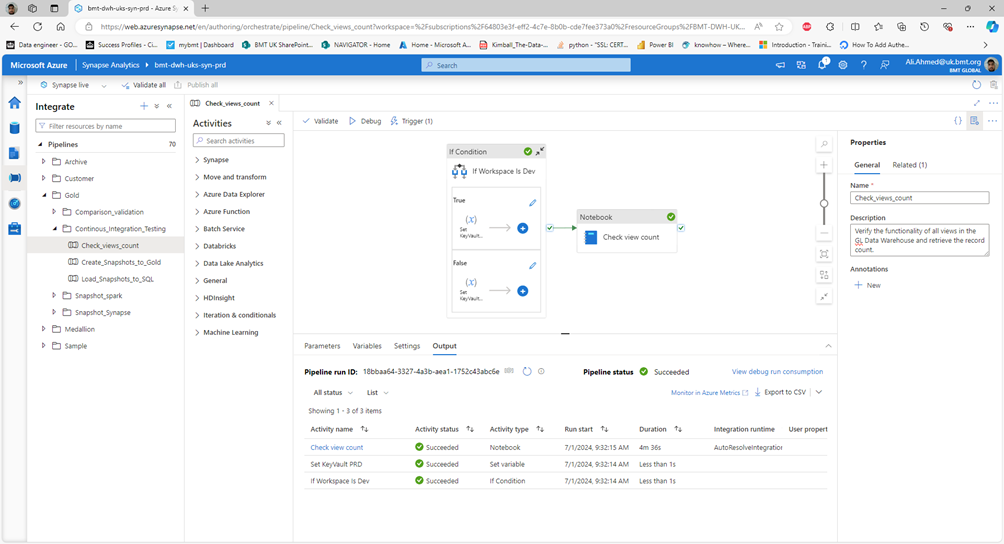
Data Lifecycle Management
Data Retention Policies: Establish data retention policies based on data classification, specifying how long data should be retained and when it should be archived or deleted.
Data Archiving: Implement archiving procedures for long-term storage of data that is no longer actively used but must be retained for compliance or historical purposes.
All source data SHALL be archived before processing (see Monitoring and Auditing)
All DataMart view SHALL be snapshot every week (on Sunday)
There is currently NO Retention Policy automatically applied in the Data Warehouse archives will be held for at least 6 years IAW the BMT Data Retention Business Procedure
Data Protection and Compliance
Compliance Frameworks: Align your data classification and handling processes with relevant regulatory frameworks (e.g., GDPR).
Data Protection Impact Assessments (DPIAs): Conduct DPIAs for projects involving sensitive data to identify and mitigate risks.
DPIA WILL be completed by the Data Owner and implemented within the Data Warehouse by the Data Engineer
Employee Training and Awareness
Training Programs: Provide regular training for employees on data classification, handling procedures, and security best practices.
Awareness Campaigns: Conduct awareness campaigns to reinforce the importance of data protection and compliance.
KnowHow SHALL describe sufficient knowledge including how to get to DataMart, Who is the owner, what is the intended purpose, Quality dimensions and return values.
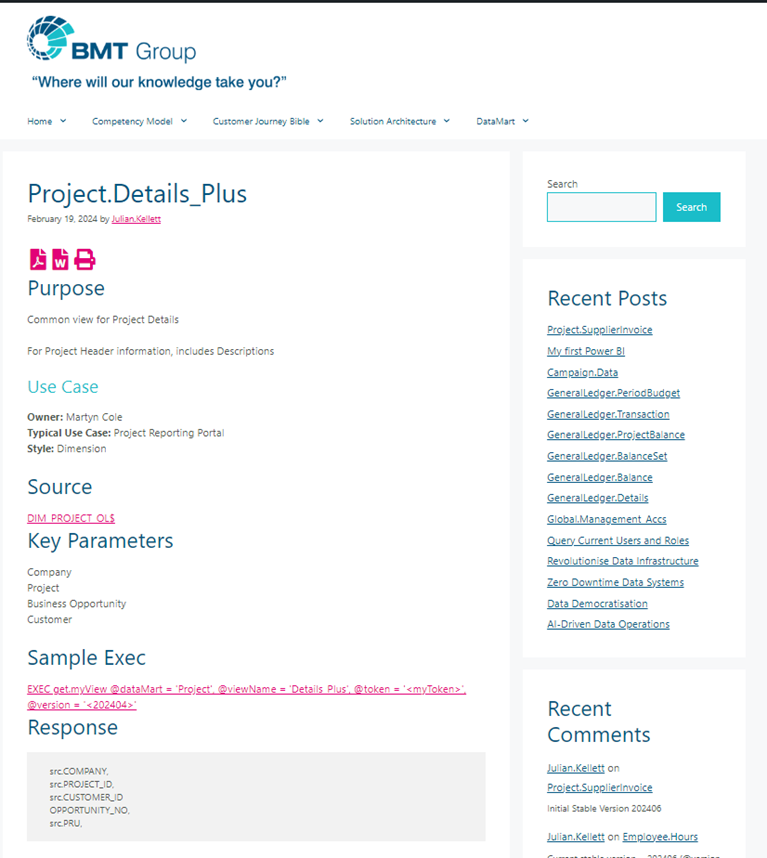
Technology and Tools
Data Loss Prevention (DLP)
DLP Solutions: Deploy DLP solutions to monitor, detect, and prevent unauthorised access, use, or transmission of sensitive data.
Policy Enforcement: Configure DLP policies to enforce data classification and handling rules.
All Data Sources SHALL be maintained in Azure
All Code Base SHALL be maintained in DevOPs
Where possible, Production Services SHOULD be updated by deployment from UAT
There is currently NO specific DLP Policy
Data Masking and Anonymisation
Data Masking: Use data masking techniques to obscure sensitive information in non-production environments.
Anonymisation: Apply anonymisation methods to remove personally identifiable information (PII) where possible, reducing the risk of data breaches.
Data Masking WILL be described by the Data Owner in the DPIA
Data Masking SHALL be performed using MD5
Data Linking Keys SHALL be performed using MD5
Data Governance Platforms
Integrated Platforms: Implement integrated data governance platforms that provide tools for data cataloguing, classification, policy management, and compliance tracking.
Workflow Automation: Use workflow automation within these platforms to streamline data classification and handling processes.
The DataMart SHALL be designed to primarily support the performance of report writing using Power BI
myBMT SHALL support the governance of the design of DataMarts
With tickets myBMT SHALL maintain a record of actions performed on DataMarts
With tickets myBMT shall support the workflow for DataMart improvements
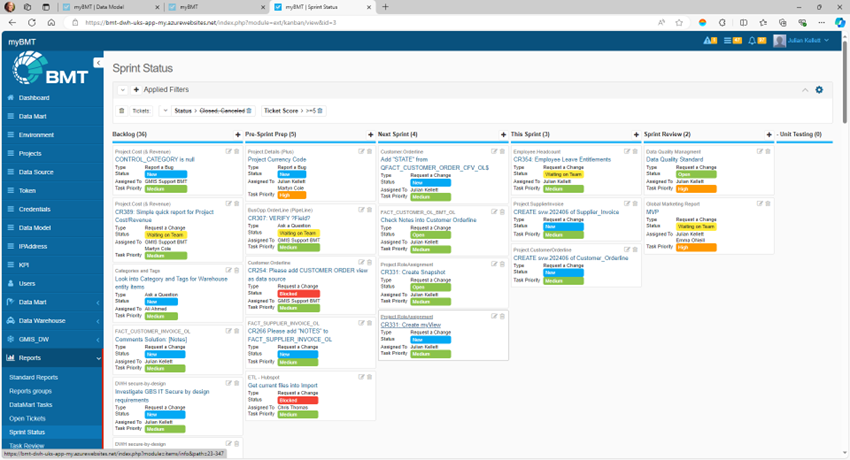
Support
Organisation/Team responsible for management of Service Desk requests/incidents.
Escalation Routes
All reports WILL provide a method of raising a Service Desk request for support. Once raised the following escalation routes will be followed.
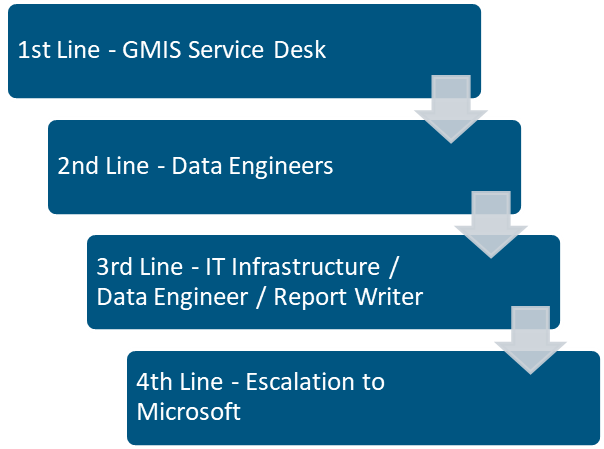
Issues Reporting (IT Service Desk)
| Stage | Activity | Comments |
| Call Received | Greet & Verify IdentityDocument Caller Details | |
| Problem Identification | Listen & Clarify | Keywords: DataWahouse, DataMart, PowerBI, Company Reporting, Company Data, SQL, Azure, Synapse Provide screenshots of Report / failure |
| Document Issue | Expected Condition: As Found Condition: Gap/Consequence: Actions/Concerns: | |
| Basic Troubleshooting | Standard ChecksKnowledge BaseInitial Resolution | Knowledge Base: knowhow – Where will our knowledge take you? (bmt-dwh-uks-app-wp.azurewebsites.net) |
| Escalation Criteria | Assess ComplexityUnresolved Issue | DataSource failures |
| Escalation Process | Document StepsInform CallerEscalate to SME/Tier 2 | Escalate to Data Engineering or Report Owner |
| Follow-Up | Update CallerConfirm ResolutionClose Ticket | Data Engineering will raise Bug Ticket in myBMT myBMT | Dashboard (bmt-dwh-uks-app-my.azurewebsites.net) |
| Post-Resolution | Collect FeedbackUpdate Knowledge BaseReview & Improve | Data Engineering will update knowhow with learning |