
(Revised for SFIA-8 Alignment)
Overview
As a Data Engineer (Grade 3) you support the development of scalable, efficient, and secure data solutions. You work closely with Data Architects, Analysts, and Business Teams to ensure the effective management of structured and unstructured data across our enterprise.
As part of the Data Engineering team, you are responsible for designing, building, and optimising data pipelines, ensuring high performance, real-time integrations, and strong data governance. You also play a key role in enabling advanced analytics and AI-driven insights.
This is an exciting opportunity for an experienced Data Engineer who is passionate about data automation, cloud engineering, and analytics enablement.
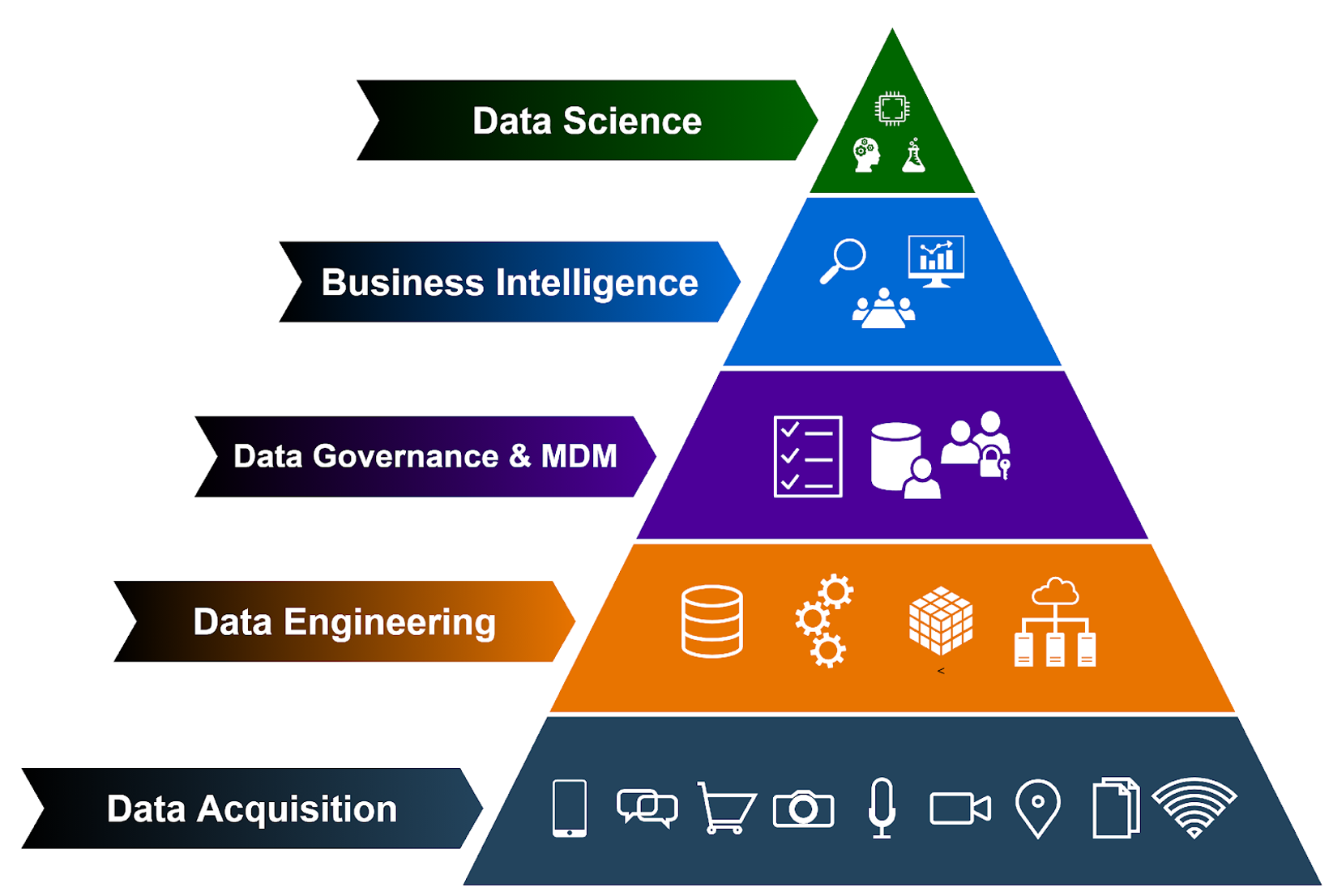
See Digital and Data Solutions Career Map
Key Responsibilities
1. Data Pipeline Development & ETL/ELT Engineering
(SFIA: Data Engineering – DENG Level 4/5)
- Design, develop, and maintain scalable, automated ETL/ELT pipelines for structured and semi-structured data.
- Optimise data ingestion and transformation processes to improve speed, accuracy, and cost-efficiency.
- Work with Azure Synapse, Databricks, and Power BI to create high-performance datasets.
- Ensure data integrity by implementing data validation and reconciliation mechanisms.
DE301: Data Pipeline Development & ETL/ELT Engineering
2. Database & Data Warehouse Design
(SFIA: Database Design – DBDS Level 4/5)
- Develop optimised data models for Data Warehouses and Data Lakes, supporting analytical workloads.
- Implement partitioning, indexing, and materialised views to enhance performance.
- Define data retention policies and implement historical tracking methods.
- Support schema evolution and data versioning across different data layers.
DE302: Database & Data Warehouse Design
3. Real-Time & API-Based Data Integration
(SFIA: Systems Integration – INCA Level 4/5)
- Develop API-based integrations for near real-time data ingestion.
- Work with streaming platforms (e.g., Apache Kafka, Azure Event Hub) to support event-driven architectures.
- Implement change data capture (CDC) strategies to keep datasets synchronised.
DE303: Real-Time & API-Based Data Integration
4. Cloud & DevOps Practices in Data Engineering
(SFIA: Methods & Tools – METL Level 4/5)
- Implement CI/CD pipelines for automated deployment of data solutions using Azure DevOps, Terraform, or GitHub Actions.
- Automate infrastructure provisioning using Infrastructure as Code (IaC).
- Ensure version control for SQL scripts, transformations, and metadata definitions.
DE30 4: Cloud & DevOps Practices in Data Engineering
5. Performance Optimisation & Cost Efficiency
(SFIA: Systems Development – DESN Level 4/5)
- Tune query performance and optimise SQL execution plans to reduce latency.
- Implement caching, data indexing, and cost-efficient storage solutions in cloud environments.
- Monitor data pipeline performance and cloud resource utilisation, optimising compute costs.
DE305: Performance Optimisation & Cost Efficiency
6. Data Governance, Security & Compliance
(SFIA: Information Security – SCAD Level 4/5)
- Implement Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC) to protect sensitive data.
- Ensure compliance with GDPR, ISO 27001, and internal data protection policies.
- Maintain data lineage, audit logs, and access controls for regulatory and security audits.
DE306: Data Governance, Security & Compliance
7. Collaboration with Data Analysts & Data Scientists
(SFIA: Specialist Advice – TECH Level 4)
- Partner with Data Analysts & BI Teams to structure data optimally for reporting tools like Power BI.
- Support Data Scientists by developing feature stores and optimising datasets for machine learning models.
- Provide guidance on best practices for querying and analysing datasets.
DE307: Collaboration with Data Analysts & Data Scientists
8. Agile & Continuous Improvement
(SFIA: Methods & Tools – METL Level 4/5)
- Work in Agile sprints, collaborating on backlog prioritisation and sprint planning.
- Maintain a continuous feedback loop to enhance data solutions iteratively.
- Participate in code reviews and knowledge-sharing sessions to improve best practices.
DE308: Agile & Continuous Improvement
What You Bring
✅ Technical Skills & Tools
- Strong experience in SQL for query optimisation, stored procedures, and indexing strategies.
- Experience with Azure Data Services (Synapse, Data Factory, Databricks, Event Hub, Blob Storage).
- Proficiency in Python or Scala for data transformation and automation.
- Hands-on experience with CI/CD pipelines and Infrastructure as Code (Terraform, ARM Templates, or Bicep).
- Familiarity with streaming technologies (Kafka, Azure Event Hub, or AWS Kinesis).
✅ Data Management & Governance
- Strong understanding of data warehousing best practices and data modelling techniques (Kimball, Data Vault, etc.).
- Experience implementing data security policies, including RBAC, data masking, and encryption.
- Knowledge of metadata management and data lineage tracking.
✅ Cloud & DevOps Mindset
- Experience deploying data solutions in cloud environments (Azure, AWS, or GCP).
- Understanding of cost-optimisation strategies in cloud data engineering.
- Strong familiarity with Git-based version control and DevOps for DataOps.
✅ Collaboration & Stakeholder Engagement
- Strong communication skills with the ability to explain technical concepts to non-technical stakeholders.
- Ability to work effectively with BI teams, Data Scientists, and Business Teams.
- Experience in Agile methodologies (Scrum, Kanban) and working in cross-functional teams.
✅ Desirable Experience
- Hands-on experience with Power BI dataset design and DAX calculations.
- Exposure to machine learning operations (MLOps) or feature engineering.
- Experience with enterprise data governance frameworks (e.g., Collibra, Informatica).
- Familiarity with containerisation (Docker, Kubernetes) in data pipelines.
Why With Us?
🌍 Work on high-impact global data projects supporting strategic decision-making.
💻 Use cutting-edge cloud data technologies including Azure Synapse, Databricks, and event-driven architectures.
🚀 Develop automation & DevOps capabilities to streamline data workflows.
📊 Partner with analysts, engineers, and scientists to deliver world-class data solutions.
🔄 Flexible hybrid working