
Data pipeline name: My Bronze Pipeline
Owner: Data Engineering Team
Used since: July 2023
Purpose: The Bronze pipeline is an automated the loading of Parquet data files from an Azure data lake storage container into tables in the staging database
Overview
This pipeline orchestrates the movement of new data that is continually appended to storage. It provides a standardised and scheduled framework to ingest large volumes of data while handling auditing, logging, and errors.
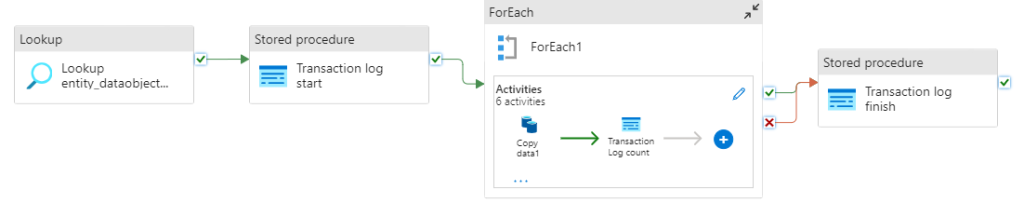
Key components of this pipeline include a Lookup Activity to fetch the list of new files needing copy, a For Each loop to iterate through each file, and Copy Activities within the loop to transfer files from storage containers to destination data warehouse tables. Stored procedures add auditing capabilities by logging the results of each copy operation into a log transaction table, recording details like file copied, row count and timestamp.
In summary, this pipeline design exemplifies efficient automation for managing data flows while ensuring robust auditing and logging functionalities.
Requirement Details
This section outlines the specific requirements that the proposed pipeline must meet in order to fulfil its intended purpose of copying Parquet files from the bronze storage container to corresponding tables in the data warehouse.
Data Source and Destination
Data Source: The pipeline is required to read Parquet files from a designated bronze storage container. These Parquet files are assumed to follow a consistent schema and format.
Data Destination: The pipeline must load data into corresponding tables within the data warehouse. Each Parquet file should be loaded into a table that matches the schema of the file.
Lookup Operation: The pipeline should include a Lookup activity that queries a control table to obtain the list of Parquet files that need to be imported during a particular run.
Pipeline Logic and Flow
For Each Loop: A For Each loop should be implemented to iterate through the list of filenames retrieved from the control table. This loop triggers the core data movement steps for each file.
Copy Activity: The Copy activity should dynamically construct the source path for each file by combining the storage container’s file path and the current file name from the loop. It should also set the destination table dynamically based on the filename.
Table Creation: If a destination table doesn’t exist, the pipeline should automatically create it with a schema matching the Parquet file being loaded.
Logging: After successfully loading each file, a Common Data Model stored procedure should be executed to insert relevant metrics, including the file name, row count, and timestamp, into the logging database.
System Architecture and Architecture Designment
The architecture of the Azure Data Factory pipeline is designed to facilitate seamless data movement from Parquet files in the bronze storage container to corresponding tables within the data warehouse. This section provides insights into the system architecture and the design considerations that support its functionality.
The architecture is structured to be modular and scalable. Each task, such as data lookup and copy, is encapsulated within separate components, enabling easy maintenance and improvements. The system’s scalability ensures it can accommodate growing data volumes without compromising performance.
A robust error-handling mechanism is integrated into the architecture. In case of failures, the pipeline manages errors and logs relevant information. This logging mechanism contributes to maintaining a comprehensive audit trail for troubleshooting and analysis.
High-Level Responsibilities and Role Breakdown:
The primary responsibilities of this pipeline revolve around the efficient extraction, transformation, and loading (ETL) of Parquet data files from the bronze storage container into data warehouse tables. These responsibilities are partitioned and assigned to subsystems that collaboratively contribute to the pipeline’s functionality.
The system is split into four major components:
Lookup Activity: This component is tasked with querying a control table to retrieve the list of Parquet files to be imported.
For Each Loop: Responsible for iterating through the retrieved filenames, triggering core data movement operations.
Copy Activity: Dynamically constructs source and destination paths for data transfer and ensures accurate loading into destination tables.
Common Data Model Stored Procedure: Inserts logging records capturing run metrics.
The higher-level components interact harmoniously to fulfil the pipeline’s objectives. The Lookup Activity feeds filenames to the For Each loop, which, in turn, coordinates the Copy Activity to transfer data from source to destination. Upon successful data loading, the Common Data Model Stored Procedure is invoked to log essential run metrics.
The chosen architectural design optimises data movement efficiency while maintaining clarity and modularity. The modular nature ensures ease of maintenance and extensibility, making it beneficial to future enhancements and alterations.
Assumptions and Prerequisites
Before implementing the pipeline described in this document, it’s important to consider several key assumptions and prerequisites. These factors ensure the successful execution of the pipeline and the accurate movement of data from the bronze storage container to the data warehouse.
Assumptions:
Control Table Setup: It is assumed that a control table exists and is properly configured with the list of table names to be imported into the data warehouse.
Prerequisites:
Access Permissions: The pipeline execution environment should have appropriate access permissions to read files from the bronze storage container, perform operations in the data warehouse (including table creation and data insertion), and execute the Common Data Model stored procedure.
Control Table Population: Prior to pipeline execution, ensure that the control table is correctly populated with the list of Parquet files that need to be imported. The table should be updated to reflect any changes in the files to be processed.
Data Warehouse Connection: A valid and properly configured connection to the data warehouse is required. This includes connection details such as server address, credentials, and any specific settings for creating or modifying tables.
Common Data Model Setup: The Common Data Model and associated stored procedure should be set up in the data warehouse. The Stored procedure should be capable of receiving the required metrics and inserting them into the appropriate table.
Storage Container Access: Ensure that the pipeline environment has the necessary access permissions to read Parquet files from the bronze storage container. This may involve providing appropriate credentials or keys.
High-Level Design
This section, will delve into the structure of the pipeline, outlining the fundamental steps that drive the continuous copying of Parquet files from the bronze storage container into corresponding tables within the data warehouse. I we discuss will explain how the pipeline orchestrates its activities to ensure accurate data movement and efficient logging.
The aim of this pipeline is to copy Parquet files from the bronze storage container into corresponding tables in the data warehouse.
Lookup: The first activity is a Lookup that queries a control table to retrieve the list of Parquet files that need to be imported into the warehouse for that run. These filenames are passed into a For Each loop, which iterates through each one triggering the core data movement.
Copy: During each iteration of the loop, the Copy activity is employed. This activity dynamically constructs the source path using both the storage container’s file path and the current file name from the loop. This ensures that the correct Parquet file is loaded for each iteration. Furthermore, the destination table name is determined dynamically based on the filename being processed. This approach guarantees that each source file is correctly loaded into a matching table within the data warehouse. If the corresponding table doesn’t already exist, it will be generated automatically.
Stored procedure: Upon successfully loading each file, a Common Data Model stored procedure is executed. This procedure inserts a record into the logging database, capturing essential run metrics such as the copied file’s name, row count, and timestamp.
The sequence of activities in this pipeline are as follows:
- Lookup operation to identify files for import.
- Initiation of logging.
- For each file:
- Truncate the destination table.
- Copying the file data into the emptied table.
- logging copy details (filename, row count, and timestamp).
Low-Level Design
This Pipeline aims to copy Parquet files from the bronze storage container into corresponding tables in the data warehouse.
This pipeline consists of 4 key activities that help achieve this goal.
Look up: The look up activity is used to find the names of the files that need importing. It does this by pointing to an existing table in the data warehouse and running a select query. This query returns a table which contains a column where each row in this column is a filename that requires importing. This array of file names can then be utilised in the foreach loop to copy the right file names from the container to the data warehouse.
For each loop: The for Each loop iterates through the value array obtained from the look up.
On each iteration The Copy activity’s source path is built dynamically using: The storage container file path and the current file name from the loop. this ensures that the correct file is copied from the correct subfolder on each iteration.
The destination table name is also set dynamically based on the looped filename. This ensures.
each source file is loaded into a matching table in the data warehouse. If the table does not exist already, it will be automatically created.
Pre-Copy Script: Before copying each file, a pre-copy script truncates the destination table. This step prevents duplicate data insertion, ensuring a clean import process.
Stored procedures: Stored procedures from the Common Data Model log the results of each copy operation into a log transaction table, recording details like file copied, row count and timestamp. The first stored procedure inserts a single row into the log transaction table, signifying that the import process is starting and specifying the number of files to be copied. the second stored procedure inserts a row for each file copied as well as including information like the number of rows copied the timestamp and a unique key for each pipeline run.