
It is essential for BMT to take a holistic approach and adopt a combination of different strategies, such as Data Ops, Data Observability, Data Mesh, and Data Quality Checks to improve the quality of data. Despite the differences in focus, one common thing among the frameworks strategies above is the need for a unified governance structure. This structure ensures data is used and managed consistently and competently across all teams and departments.
The DOM includes a series of initiatives aimed at continually elevating data quality standards across BMT’s data environment.
- DataOps & Continuous Integration: Automated testing and version control support consistent, reliable data processing.
- Data Observability and Monitoring: Real-time monitoring for anomalies in data ingestion, consistency, and accuracy.
- Data Mesh Principles for Decentralised Ownership: Empowers domain-specific teams to manage data while adhering to centralised governance standards.
- Feedback Loops: Mechanisms for data users to provide input, promoting continuous refinement of data standards and procedures.
Data Ops (CI/CD)
Continuous Integration and Continuous Deployment ensure that changes and updates to data pipelines are automatically tested, integrated, and deployed to production, facilitating consistent and reliable data processing and delivery.
In dynamic data environments where data sources, formats, and requirements evolve rapidly, CI/CD provides a framework for automating the testing, integration, and deployment of data pipelines. This ensures that changes and updates to data pipelines are rigorously tested and validated before being seamlessly deployed to production environments.
In Data Engineering, this involves automating testing new ETL code, validating data schema, monitoring data quality, detecting anomalies, deploying updated data models to production, and ensuring that databases or data warehouses have been correctly configured.
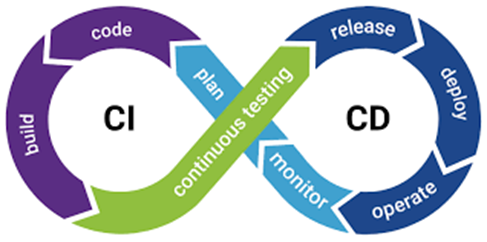
| CI/CD Development Lifecycle |
- CI/CD Quality Actions in Data Pipelines
| Principle | Activity | |
| CI | Automated Testing | Automated tests check the integrity and quality of data transformations, ensuring that data is processed as expected and any error is spotted early. |
| Version Control | Data pipeline code (e.g., SQL scripts, Python transformations) is stored in repositories like Git, allowing tracking and managing changes. | |
| Consistent Environment | CI tools can run tests in environments that mirror production, ensuring that differences in configuration or dependencies don’t introduce errors. | |
| Data Quality Checks | These might include checks for null values, data range violations, data type mismatches, or other custom quality rules. | |
| CD | Automated Deployment | Once code changes pass all CI checks, CD tools can automate their deployment to production, ensuring seamless data flow. |
| Monitoring and Alerts | Once deployed, monitoring tools keep track of the data pipeline’s performance, data quality, and any potential issues. Automated alerts can notify on discrepancies. | |
| Development Branch Management | In case an issue is identified post-deployment, CD processes allow for quick rollbacks to a previously stable state of the data pipeline. |
Data Observability
The overarching goal of Data Observability is proactive problem-solving, where any anomalies or discrepancies are swiftly identified and rectified before they escalate into issues. Through continuous monitoring and analysis, data observability helps to maintain the reliability, accuracy, and accessibility of their data assets, thereby fostering trust and confidence in data-driven decision-making.
- Principles of Data Observability
| Principle | Activity | So that … |
| Freshness | Ensure that data is up-to-date and reflects the most recent state of the source systems | users can make decisions based on timely and accurate information, leading to more informed and effective actions. |
| Distribution | Monitor how data is spread across systems and locations to ensure that it falls within acceptable ranges and thresholds | potential issues such as data skew or imbalance can be identified and addressed promptly, maintaining data quality and integrity across the distributed environment. |
| Volume | Track the volume of data being ingested, processed, and stored | capacity planning and resource allocation can be optimised, preventing infrastructure overload or resource contention and maintaining efficient data processing. |
| Schema | Validate data schema consistency and evolution over time | data compatibility and interoperability are maintained, preventing errors and inconsistencies that could disrupt downstream processes or analyses. |
| Lineage | Capture and visualise the lineage of data, including its origins, transformations, and destinations | data provenance and impact analysis can be performed, enabling users to trace data back to its source and understand its journey through the data pipeline. |
Data Mesh
The Data Mesh decentralises data ownership by transferring the responsibility from the central data team to the business units that create and consume data.
By decentralising data ownership to domain teams, Data Mesh promotes agility, innovation, and accountability within BMT. It enables faster decision-making, facilitates collaboration across business units, and empowers domain experts to derive actionable insights from data more effectively.
It operates on the principles of domain-driven design, product thinking, and federated governance.
- Data Mesh Principles
| Principle | Activity | So that… |
| Domain-oriented Decentralised Data Ownership and Architecture: | Implement data flows to seamlessly connect operational systems with analytics and business intelligence (BI) systems | domain teams can own and manage their data independently, fostering agility and innovation within their domains. |
| Data as Product: | Document clear source-to-target mappings for transparency and traceability | data is treated as a valuable product, ensuring that it is well-understood, curated, and accessible for consumption by domain teams. |
| Self-service Infrastructure as a Platform: | Provide a data developer portal (myBMT & Knowhow) | domain teams can autonomously access and utilise data infrastructure and tools, enabling them to build, deploy, and manage data pipelines and applications without the need for extensive support from centralised teams. |
| Federated Computational Governance: | Provide support for the development and maintenance of data analysis/analytics systems | Best practice and computational learning can be distributed, allowing domain teams to govern their data processing and analytics workflows according to their specific needs and requirements. |
Data Rules & Quality Checks
Data Quality Rules/Checks, allows the Data Specialist to directly address and uphold the quality dimensions of accuracy, completeness, and consistency, ensuring that the data meets the desired standards and remains reliable for analysis and decision-making.
- Data Quality Rules
| Principle | Activity | So that … |
| Accuracy | Ensure that data is accurate and free from errors or inaccuracies | stakeholders can make reliable decisions based on trustworthy information, leading to improved business outcomes and performance. |
| Completeness | Verify that all required data elements are present and accounted for | analyses and reports are comprehensive and representative of the entire dataset, reducing the risk of biased or incomplete insights. |
| Consistency | Enforce consistency in data values and formats across systems and sources | data can be seamlessly integrated and aggregated, avoiding discrepancies and ensuring compatibility for downstream processes and analyses. |
| Missing Data | Identify and flag instances where data is missing or incomplete | gaps in the dataset can be addressed promptly, preventing erroneous conclusions or decisions based on incomplete information. |
| Duplicate Data | Detect and eliminate duplicate entries or records within the dataset | data integrity is maintained, preventing overcounting or inaccuracies in analyses and ensuring a single source of truth for reporting and decision-making. |
| Format Validation | Validate data formats to ensure consistency and adherence to predefined standards | data can be accurately interpreted and processed by downstream systems or applications, minimising errors and compatibility issues. |
- Management of Error Precursors
| Risk/Issue | Mitigation |
| Dependency Failures: Failures in upstream systems or dependencies affecting data availability.Unreliable third-party data sources or services.Failure to handle dependency failures gracefully within the pipeline. | Dependency Isolation: Isolate dependencies within the data pipeline to minimise the impact of failures on other components. Use service boundaries, microservices architecture, and message queues to decouple dependencies and prevent cascading failures from propagating throughout the pipeline. |
| Data Pipeline Configuration Errors: Incorrect configuration settings for data pipeline componentsMisconfigured data connections or permissionsChanges to pipeline configurations without proper testing or validation | Configuration Management System: Implement a robust configuration management system to centralise and manage configuration settings for data pipeline components. Utilise version control systems, such as Git or Subversion, to track changes to configuration files and ensure consistency across environments. |
| Data Quality Issues: Missing valuesIncorrect data formatsInconsistent data across sources | Data Quality Monitoring: Implement data quality monitoring processes to continuously monitor the quality of incoming data. Set up alerts or notifications to flag instances of missing values, incorrect formats, or inconsistencies in real-time, allowing for prompt remediation. |
| Resource Exhaustion: Exhaustion of system resources (e.g., memory, CPU, storage) leading to pipeline failuresInefficient resource utilisation or allocation within the pipeline infrastructureFailure to scale resources dynamically based on workload demands | Modularisation: Break down the pipeline into modular components to improve scalability, maintainability, and flexibility. Design modular components that perform specific tasks or functions, such as data ingestion, transformation, and loading, and orchestrate these components in a cohesive and efficient manner. |
| Monitoring and Alerting Failures: Ineffective monitoring of pipeline health and performanceFailure to detect and alert on anomalies or errors in a timely mannerLack of visibility into pipeline status and health metrics | Proactive Health Checks: Conduct proactive health checks of the data pipeline at regular intervals to identify potential issues before they escalate. Use automated scripts or monitoring tools to perform health checks on data sources, processing components, and downstream systems. |
| Data Security Breaches: Unauthorised access to sensitive data within the pipelineData leaks or breaches due to inadequate security measuresInsider threats or malicious activities compromising data integrity | Role-Based Access Control (RBAC): Implement role-based access control (RBAC) mechanisms to manage data pipeline permissions and access rights. Define roles and permissions for different user groups or personas, and assign permissions based on job responsibilities and data access requirements to prevent unauthorised access or misuse of data. |
| Data Integration Problems: Incompatibility between different data formats or schemasIssues with data synchronisation between systems or databasesData loss or corruption during integration processes | Schema Standardisation: Establish standardised data schemas or formats to ensure compatibility between different systems or databases. Define and enforce data standards to facilitate seamless integration and minimise conflicts or inconsistencies in data structures. |
| Data Transformation Errors: Logic errors in data transformation processesInaccurate data aggregations or calculationsMismatched data types during transformation | Continuous Improvement Practices: Foster a culture of continuous improvement by regularly reviewing and optimising data transformation processes. Encourage feedback from stakeholders and team members to identify areas for enhancement and implement iterative improvements to increase the efficiency and reliability of data transformations. |
| Network Connectivity Issues: Network outages or latency affecting data transmission between componentsPacket loss or network congestion impacting data transfer reliabilityInadequate network bandwidth for data pipeline requirements | API Integration: Utilising APIs (Application Programming Interfaces) for data transmission between components can provide a standardised and reliable communication mechanism. APIs offer well-defined interfaces for data exchange, allowing you to establish robust connections and implement error handling mechanisms to handle network outages or latency effectively. |
| Data Processing Bottlenecks: Slow or inefficient processing of large volumes of dataResource constraints leading to processing delaysInadequate scalability of processing infrastructure | Reorganise Pipeline: By reorganising the pipeline for efficiency, you can optimise resource utilisation, reduce processing latency, and improve overall system performance, enabling faster and more scalable data processing workflows. |