
Design methodology, development platform, hardware requirements, database. All Software Quality Procedures
Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration and Continuous Deployment (CI/CD) ensures that changes and updates to data pipelines are tested, integrated, and deployed to production, facilitating consistent and reliable data processing and delivery. In dynamic data environments where sources, formats, and requirements evolve rapidly, CI/CD provides a robust framework for handling these changes.
Continuous Integration (CI)
Continuous Integration is an agile practice where developers frequently integrate their code changes into a shared repository, ideally several times a day. Each integration is verified by building the application in the development environment and running tests against it. The main goals of CI are to detect errors quickly, reduce integration problems, and ensure that the software is always in a potentially releasable state.
Continuous Deployment (CD)
Continuous Deployment is an extension of Continuous Integration that focuses on deploying every change that passes the quality tests into production. The goal is to deliver new features, improvements, and bug fixes to users as quickly and safely as possible without manual intervention.
CI/CD in Data Engineering
Specifically, in Data Engineering, CI/CD facilitates the testing of new ETL code, validates data schemas, monitors data quality, detects anomalies, deploys updated data models to production, and ensures proper configuration of databases and data warehouses. This rigorous process guarantees that changes are thoroughly tested and seamlessly integrated into production environments.
By implementing CI/CD in Data Engineering, the team can handle rapid changes in data environments, maintain high-quality data processing, and ensure reliable delivery of data to stakeholders.
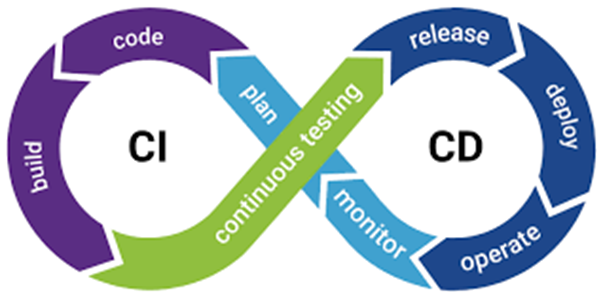
- CI/CD Development Lifecycle
Common Data Model
At the core of BMT’s data warehouse architecture is the Common Data Model (CDM), which serves as the foundation for representing the organisation’s core business processes and common form designs. The CDM supports dimensional modelling, where data is structured into measurement facts and descriptive dimensions, enabling efficient querying and analysis. Dimensional models, instantiated as star schemas or cubes in relational databases, provide a structured framework for organising and accessing data, facilitating reporting and analytics processes.
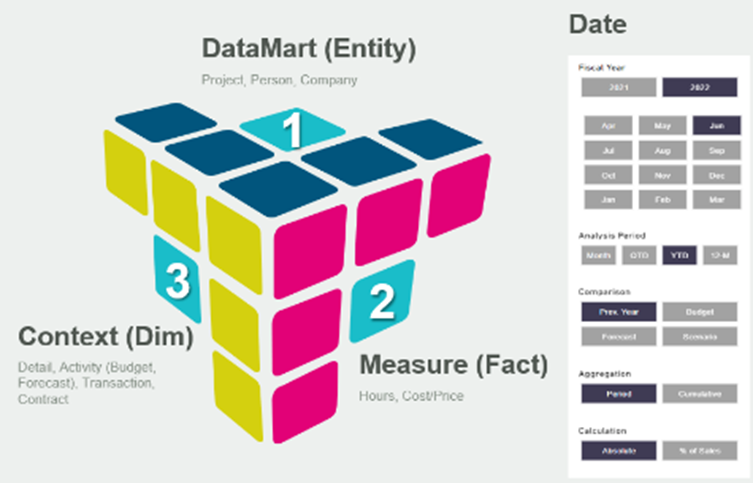
Common Data Model (Cube)
Medallion Lakehouse architecture
The Medallion Lakehouse represents successive levels of data refinement, with each stage adding value and sophistication to the data as it progresses towards its ultimate purpose of enabling informed decision-making and driving business success.
Bronze Data Layer:
The bronze stage focuses on ingesting raw data from multiple sources without much transformation. The emphasis is on capturing all available data in its original form, ensuring completeness and preserving the integrity of the source data. Quality checks are applied to identify and address any issues with data integrity or consistency. The goal of the bronze stage is to create a foundational dataset that serves as the basis for further processing and refinement.
- Maintains the raw state of the data source.
- Is appended incrementally and grows over time.
- Can be any combination of streaming and batch transactions.
Silver Data Layer:
In the silver stage, the raw data from the bronze pipeline undergoes additional processing and transformation to make it more structured and usable for analysis. This involves cleaning the data, standardising formats, resolving inconsistencies, and enriching it with additional context or metadata. Data quality checks are intensified to ensure accuracy and reliability. The silver stage produces a refined dataset that is well-prepared for analytical purposes and serves as a reliable source for business insights.
- Silver Layer represents a validated, enriched version of our data that can be trusted for downstream analytics.
Gold Data Layer:
The gold stage represents the highest level of refinement in the data pipeline. Here, the data is further enhanced and optimised for specific analytical or operational needs. Advanced transformations, aggregations, and calculations are applied to derive valuable insights and support decision-making processes. Data governance measures are rigorously enforced to maintain data integrity, security, and compliance. The gold stage delivers curated datasets of the highest quality, providing actionable insights that drive business outcomes and strategic initiatives.
- Gold tables represent data that has been transformed into knowledge, rather than just information.
- Analysts largely rely on gold tables for their core responsibilities, and data shared with a DataMart would rarely be stored outside this level.